

Performance requirements get documented. Security constraints get reviewed. Reliability targets get approved. Then six months later, the system crashes under load, sensitive data leaks through an unmonitored API, and response times crawl to 8 seconds while everyone scrambles to figure out which requirement was supposed to prevent this.
Non-functional requirements fail differently than functional ones. A missing feature is obvious. A performance bottleneck that only appears at 500 concurrent users? That surfaces during Black Friday when your payment gateway starts timing out.
The core problem isn't writing NFRs. Most teams actually overdocument them. The problem is operational continuity — keeping those requirements alive and measurable from initial spec through production monitoring. Requirements die in the handoffs between phases, get lost in sprint planning, and disappear entirely once code ships.
The three-phase death of NFRs
NFRs typically die in three predictable phases, each with its own operational breakdown.
Phase 1: Specification decay
Teams write NFRs like wish lists instead of contracts. "System should be fast" becomes a requirement. "Application must be secure" gets approved by stakeholders. These aren't specifications — they're prayers.
Even when teams write measurable NFRs like "API response under 200ms for 95% of requests," they rarely specify the context. Under what load? Which endpoints? What infrastructure? During peak hours or average traffic?
The specification problem compounds when NFRs live scattered across documents. Security requirements hide in one spreadsheet, performance targets in another, compliance needs in a third. No single source shows the complete non-functional picture.
Phase 2: Development amnesia
Sprint planning focuses on user stories. NFRs become afterthoughts, mentioned in retrospectives when something breaks. Developers implement features without knowing the performance budget. QA tests functionality without stress testing the infrastructure limits.
Even when NFRs make it into acceptance criteria, they're often unverifiable during development. A requirement like "maintain 99.9% uptime" can't be tested in a two-week sprint. It needs production data over months.
The handoff between development and operations is where NFRs go to die. Dev teams mark stories complete when functional tests pass. Ops teams inherit systems without knowing the original performance assumptions or security constraints.
Phase 3: Production blindness
Systems ship with monitoring that tracks availability and basic metrics but rarely maps back to original NFRs. The requirement specified "page load under 2 seconds for 90% of users" but production monitoring only tracks average response time across all requests.
When performance degrades or a security incident hits, teams can't trace the failure back to a specific requirement, owner, or decision point. The post-mortem becomes archaeology — digging through old documents trying to figure out what the system was supposed to do versus what it actually does.
Building an NFR continuity system
The solution isn't more documentation or stricter governance. It's operational continuity — traceable paths from specification to production monitoring with clear ownership at each step.
Stop losing track of critical project requirements.
GoReqly helps you capture, organize, and track every requirement with precision and clarity.
- Centralized requirements repository
- Collaborative editing & commenting
- Traceability & version control
No credit card required
NFR specification templates that survive handoffs
Generic NFR templates create generic failures. Each NFR category needs specific patterns that force measurable, contextual specifications.
Performance NFRs need four components:
-
Metric (response time, throughput, resource usage)
-
Target value with percentile (200ms for P95)
-
Context conditions (standard load, peak load, degraded mode)
-
Measurement point (client-side, server-side, database)
A complete performance NFR looks like: "User search API returns results in under 200ms for 95th percentile of requests, measured server-side, under standard load of 100 concurrent users."
Security NFRs require:
-
Threat model reference
-
Specific controls or standards
-
Validation method
-
Exception handling process
Instead of "implement authentication," specify: "All API endpoints require OAuth 2.0 bearer tokens validated against central authority, with 401 responses for invalid tokens, following OWASP authentication guidelines."
Reliability NFRs must include:
-
Availability target with measurement window
-
Failure scenarios and recovery expectations
-
Degradation modes
-
Incident response triggers
Rather than "ensure high availability," document: "Payment service maintains 99.95% availability measured monthly, auto-scales at 70% CPU, degrades to queue mode during database outages, triggers PagerDuty at 5-minute downtime."
Acceptance criteria patterns that enforce NFRs
Acceptance criteria often break during QA handoffs, but NFRs need special patterns to survive development cycles.
``
GIVEN standard production load profile (500 users, 80/20 read/write)
WHEN system runs for 30 minutes
THEN 95% of API calls complete under 300ms
AND memory usage stays below 4GB
AND no requests timeout
``
``
GIVEN unauthenticated user
WHEN accessing protected endpoint
THEN receive 401 response within 50ms
AND attempt logged to security audit stream
AND rate limiting engages after 10 attempts
``
``
GIVEN primary database offline
WHEN user requests data
THEN system switches to cache-only mode within 5 seconds
AND displays stale data warning
AND queues write operations for replay
``
These patterns make NFRs testable during sprints rather than hoping they hold up in production.
CI/CD checks that enforce continuous validation
Automated pipelines should validate NFRs at build time, not just run unit tests. This requires specific tooling integration at each pipeline stage.
Build-time checks cover three areas: performance budget validation (bundle size, query complexity), security scanning (dependency vulnerabilities, code patterns), and compliance validation (data handling, encryption requirements).
Pre-deployment gates should require load test results against NFR thresholds, a clean security scan with zero critical issues, and performance regression tests comparing against baseline.
After deployment, the validation continues. Synthetic monitoring confirms NFR targets are holding. Real user monitoring validates percentile requirements under actual traffic. Security posture scanning checks the deployed infrastructure, not just the code.
A financial services platform I worked with embedded their NFRs directly into deployment pipelines. Transaction processing time requirements became automated performance tests that blocked deployments if P99 latency exceeded 500ms. Security NFRs triggered static analysis checks for PCI compliance. Zero NFR-related production incidents in 18 months, compared to monthly fires before that.
Monitoring contracts that connect production to requirements
Production monitoring typically tracks symptoms, not requirements. NFRs need monitoring contracts that explicitly map metrics to original specifications.
Structure monitoring contracts with five elements:
-
Requirement reference Link to original NFR specification
-
Metric definition Exact calculation and measurement point
-
Alert thresholds Warning and critical levels based on NFR
-
Owner designation Team and individual responsible
-
Remediation runbook Steps when thresholds breach
``
NFR-PERF-001: Search API Response Time
Requirement: 200ms P95 response time under standard load
Metric: apiresponsetime_seconds{endpoint="/search", quantile="0.95"}
Warning: > 180ms for 5 minutes
Critical: > 200ms for 2 minutes
Owner: Search Team / Sara Chen
Runbook: https://runbooks/search-performance-degradation
``
This creates accountability and speeds up incident response by connecting symptoms directly to requirements and owners.
Embed runbook links directly in alert definitions so responders have the exact remediation steps in the alert context.
This workflow shows the path from NFR specification to monitoring and ownership.
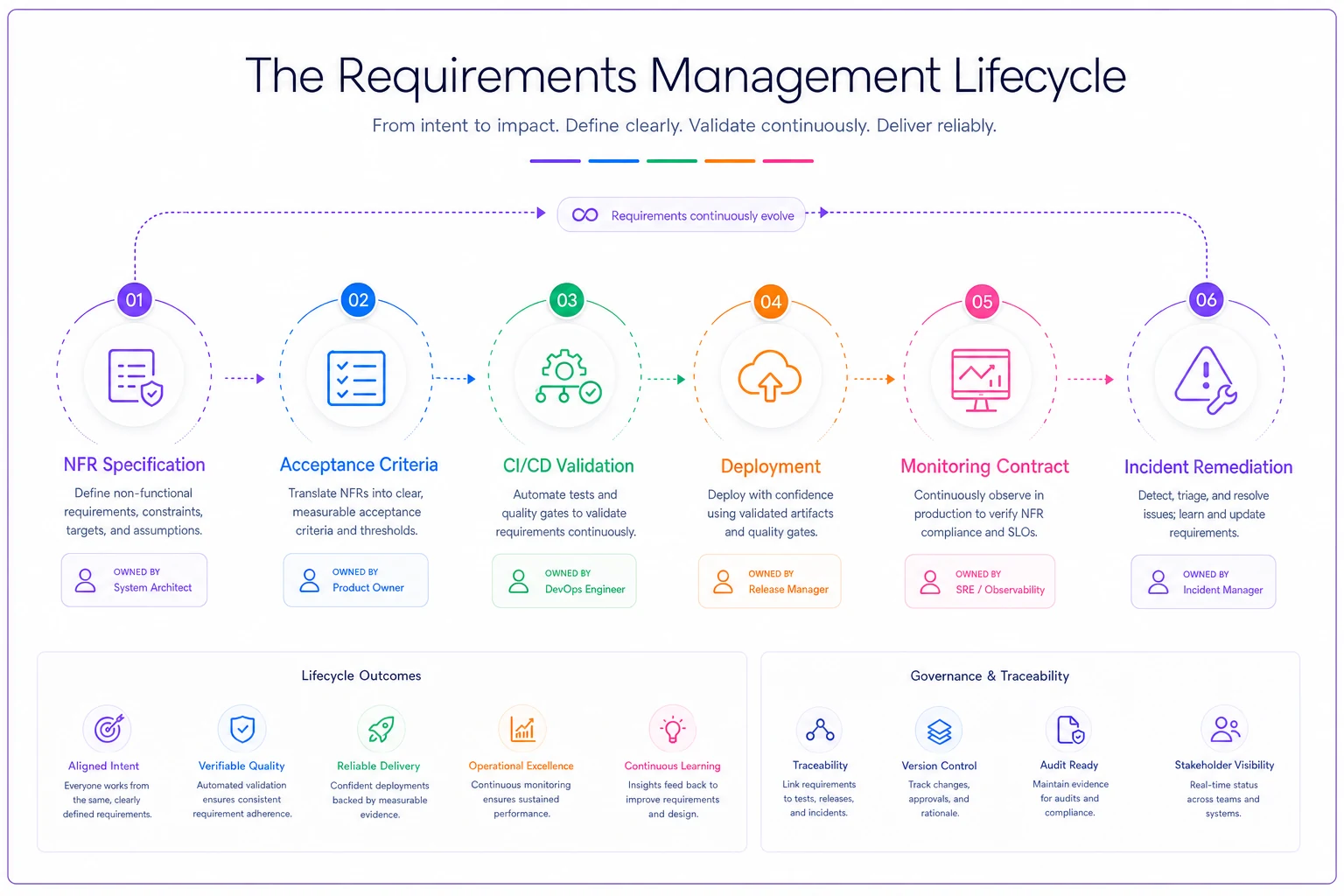
Use this flow as a template to ensure each requirement has a clear owner and measurement point.
Risk registers specifically for NFR degradation
Traditional requirements management rarely addresses technical debt systematically, but NFRs need active risk tracking because they degrade over time.
Build an NFR risk register tracking:
| NFR ID | Risk Description | Probability | Impact | Mitigation | Owner | Review Date |
|---|---|---|---|---|---|---|
| PERF-001 | Database growth degrades query performance | High | Critical | Index optimization, archival strategy | Data Team | Monthly |
| SEC-003 | OAuth token validation adds latency | Medium | Moderate | Token caching, async validation | Security Team | Quarterly |
| REL-002 | Single point of failure in payment gateway | Low | Critical | Multi-region deployment, circuit breaker | Platform Team | Quarterly |
The risk register forces teams to acknowledge that NFRs aren't static. A system meeting performance requirements today might fail those same requirements in six months as data grows or usage patterns shift.
Regular risk review meetings should assess changes in usage patterns affecting NFRs, technical debt accumulating against requirements, infrastructure changes impacting performance, and new threats affecting security postures.
Trace matrices that survive organizational change
The biggest NFR killer? Team reorganizations and personnel changes. Requirements knowledge walks out the door with people who leave.
Create living trace matrices that connect NFR specifications to implementation components, components to monitoring rules, monitoring rules to responsible teams, and teams to escalation paths.
This isn't a static document. Build it into your requirements management system where updates trigger notifications. When a team reorganizes, the matrix shows exactly which NFRs need new owners. When monitoring rules change, the matrix surfaces which requirements might be affected.
Real scenario: e-commerce platform NFR recovery
An e-commerce platform handling roughly $2M in monthly transactions discovered their NFRs were completely disconnected from operations. Page load times averaged 4 seconds despite original requirements specifying 2-second maximums. Security scans found a dozen critical vulnerabilities that should have been caught by NFR-mandated checks.
Sprint 1: Documented all existing NFRs using category-specific templates. Found 67 NFRs scattered across 8 documents, with 23 unmeasurable and 15 duplicates. Consolidated to 29 measurable NFRs with clear ownership.
Sprint 2: Added NFR checks to CI/CD pipeline. Load tests now ran automatically against performance NFRs. Security scans blocked deployments with critical issues. This immediately caught 3 performance regressions that would have reached production.
Sprint 3: Deployed monitoring contracts for all NFRs. Each requirement mapped to specific metrics, alerts, and runbooks. Created a monthly risk review process.
Results after 6 months: page load times dropped to 1.8 seconds P95, zero security vulnerabilities reached production, performance incidents reduced by roughly 78%, and mean time to resolution improved from around 3 hours to 35 minutes.
The key wasn't writing better NFRs — it was maintaining operational continuity from specification through production monitoring.
Common NFR traceability failures
Over-abstraction: Teams build complex traceability frameworks that nobody maintains. A simple spreadsheet updated weekly beats an elaborate system updated never.
Metric mismatch: NFRs specify one metric but monitoring tracks another. "Page load time" in requirements might mean time-to-interactive, but monitoring measures time-to-first-byte.
Ownership gaps: NFRs fall between teams. Performance requirements need platform team infrastructure but application team code optimization. Without clear ownership, both teams assume the other handles it.
Tool fragmentation: Requirements live in Jira, tests in TestRail, monitoring in Datadog, documentation in Confluence. No single view shows NFR status across the lifecycle.
Review theater: Teams perform quarterly NFR reviews that generate reports but no action. Reviews need defined triggers for updating requirements, adjusting monitoring, or addressing risks.
Making NFR traceability operational
The difference between NFRs that survive to production and those that die in development isn't documentation quality — it's operational integration.
Stop treating NFRs as special cases requiring separate processes. Embed them into existing workflows:
-
Add NFR templates to story creation
-
Include performance budgets in definition of done
-
Make security scans part of standard CI/CD
-
Review NFR risks during sprint retrospectives
Effective requirements KPIs drive specific actions, and NFR traceability needs the same approach. Track metrics that actually matter:
-
Percentage of NFRs with automated validation
-
NFR-related production incidents per month
-
Time from NFR violation to detection
-
NFR test coverage in CI/CD pipeline
AI-powered operational software can reduce a lot of the manual overhead here. These platforms can automatically extract NFRs from scattered documents, generate test cases, and maintain trace links as systems evolve — including keeping ownership mappings intact through reorgs, which is where things usually fall apart.
The goal isn't perfect documentation or full automation. It's maintaining enough operational continuity that when something breaks at 2 AM, the on-call engineer can quickly trace from the alert to the requirement to the owner to the fix. That's when NFR traceability actually proves its worth — under pressure, not just in quarterly reviews.
NFRs will keep failing in delivery until teams stop treating them as documentation exercises and start treating them as operational contracts that need continuous validation from specification through production. The tooling exists. The patterns work. The question is whether teams will commit to the operational discipline required to keep requirements alive through the entire system lifecycle.
Ready to transform your product delivery?
Join 2,000+ teams using GoReqly to improve requirements accuracy, reduce rework, and accelerate time to market.


